Building a Scalable Microservices Architecture: A Visual Guide
Table of ContentsTap to expand
Building scalable backend systems is one of the most exciting, yet notoriously complex, challenges in software engineering. For a long time, the default approach was the monolithic architecture—a single, unified codebase where all business logic, UI rendering, and database connections resided together. While monoliths are incredibly easy to start with, they inevitably become victims of their own success.
As a monolithic application grows, it becomes a tangled web of dependencies. Scaling becomes a nightmare because you must duplicate the entire application even if only one module is experiencing high traffic. Deployment bottlenecks emerge as dozens of developers are forced to merge into the same massive release pipeline. Finally, you face technology lock-in; adopting a new language or framework requires rewriting the entire Goliath.
Enter microservices. Microservices architecture is a modern approach to software development where a large application is built as a suite of small, independent services. Each service runs its own process, manages its own data, and communicates over lightweight mechanisms like HTTP or messaging queues. They are decoupled, highly specialized, and inherently scalable.
The goal of this post is to provide a clear, structured, and visual guide to understanding the microservices ecosystem. We will demystify the core components, explore fundamental communication patterns, and look at data management strategies.

1. The Core Components of a Microservices Ecosystem
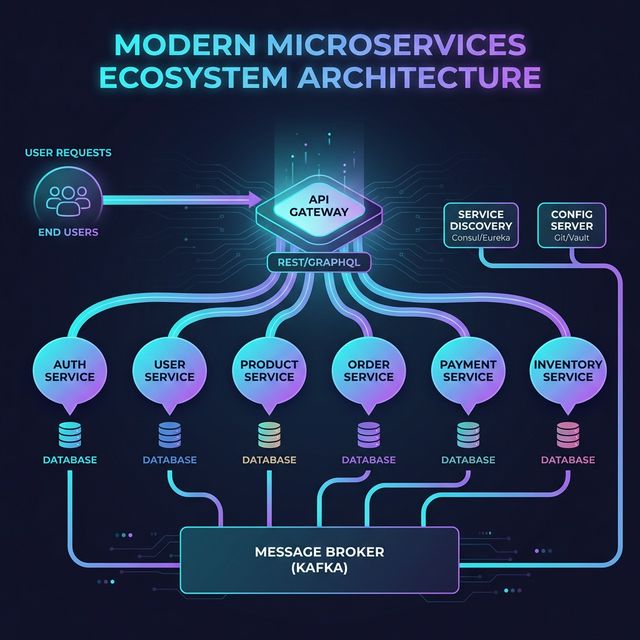
A microservices architecture is more than just breaking code apart; it requires a robust supporting ecosystem to keep the highly decoupled pieces functioning as a cohesive unit. Let's break down the essential building blocks.
First is the API Gateway. Think of this as the front door to your entire system. Instead of client applications (like mobile apps or web frontends) trying to memorize the addresses of dozens of different microservices, they simply send all requests to the API Gateway. The gateway handles routing the request to the correct internal service. It also acts as the primary enforcement point for cross-cutting concerns like authentication, SSL termination, and rate limiting.
Because services in a distributed system frequently scale up and down (changing IP addresses dynamically), we need Service Discovery. Service Discovery acts like a dynamic phone book for your cluster. When Service A needs to talk to Service B, it asks the Service Discovery registry for B's current, active address, ensuring reliable connections even as underlying infrastructure shifts.
Next, maintaining configuration files across dozens of independent repositories is an operational nightmare. A Configuration Server solves this by centralizing all settings management. Services fetch their specific configurations (like database credentials or feature flags) dynamically at startup, allowing you to change environments without recompiling code.
To prevent tight coupling between services, we heavily rely on a Message Broker (such as Apache Kafka or RabbitMQ). This enables asynchronous communication. Instead of Service A waiting for Service B to respond, A simply drops an event into the broker. Service B can pick it up and process it whenever it is ready, drastically improving system resilience.
Finally, the golden rule of microservices: Independent Databases. Each microservice must own its own data. This ensures true decoupling; if the Inventory database goes down, the User Authentication service remains perfectly operational.
2. How Microservices Communicate: Synchronous vs. Asynchronous
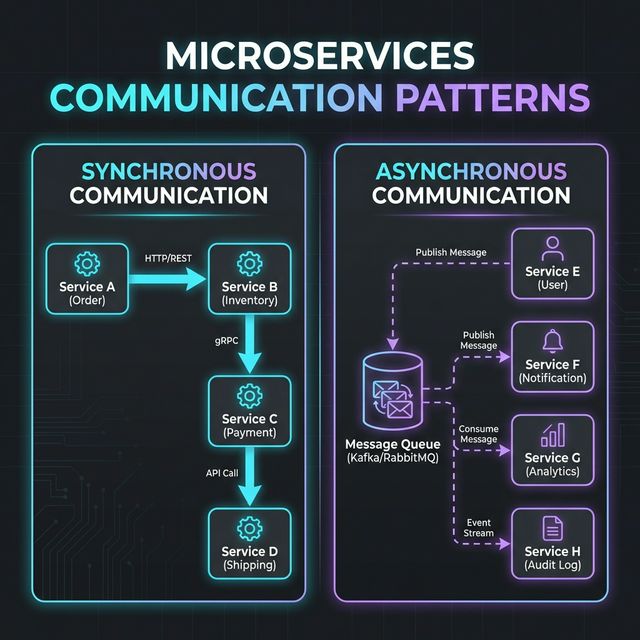
When you split an application into dozens of pieces, they still need to talk to each other to fulfill complex business transactions. This communication falls into two primary categories.
Synchronous Communication happens in real-time. Service A sends a direct request to Service B (usually via REST APIs or gRPC) and halts execution while waiting for a response. The primary advantage here is simplicity and immediate consistency—you know right away if the operation succeeded or failed. However, the downside is severe tight coupling. If Service B is slow, Service A becomes slow. If Service B crashes, the transaction fails entirely.
Asynchronous Communication, on the other hand, is completely decoupled and relies on event-driven architecture. Service A publishes an event to a Message Queue (e.g., "Order Created") and immediately moves on. Service B, which subscribes to that queue, eventually processes the event. The pros are massive: ultimate fault tolerance and system resilience. If Service B goes offline, the messages simply wait safely in the queue until it spins back up. The main con is complexity; debugging asynchronous flows is difficult, and you must design your UI to handle "eventual consistency."
Knowing when to choose which pattern is the hallmark of a senior engineer. Use synchronous communication when you absolutely need an immediate query result (e.g., checking if a user exists). Use asynchronous communication for state changes, background processing, and any workflow that doesn't strictly require the user to wait staring at a loading spinner.
3. Data Management & Distributed Transactions
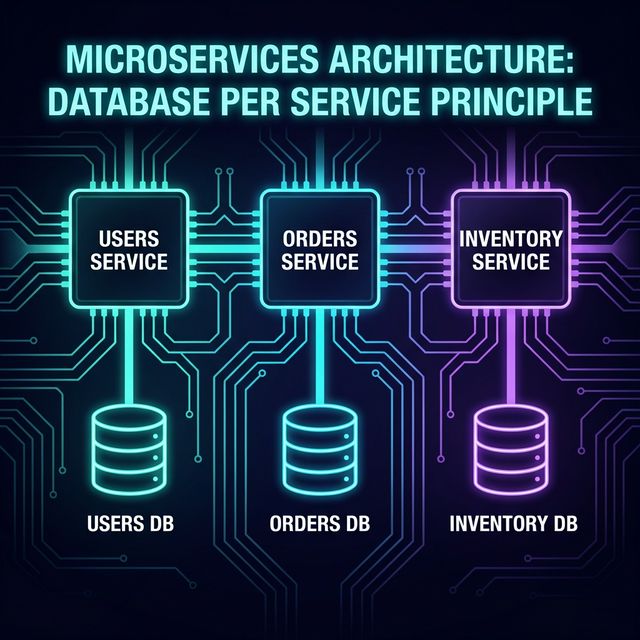
Data is the hardest part of distributed systems. The foundational "Database per Service" Principle dictates that a service's database can only be accessed by that specific service's API. There is no shared database layer. This guarantees extreme data independence and allows different teams to choose the best database technology for their specific workload (e.g., Postgres for transactions, Neo4j for graphs).
However, this independence introduces the massive challenge of Distributed Transactions. In a monolith, if a user places an order, you can update the Orders table and the Inventory table in a single, ACID-compliant database transaction. If one fails, the database automatically rolls everything back. In a microservices architecture, the Order service and Inventory service have different databases. You cannot use a traditional transaction spanning both.
The industry-standard solution to this is the Saga Pattern. A Saga is a sequence of local transactions where each local transaction updates the database inside a single microservice and then publishes an event to trigger the next transaction in the saga. If a step fails, the Saga executes a series of compensating transactions (essentially "undo" operations) to revert the changes made by the previous steps. Sagas can be implemented via Choreography (services react to each other's events independently) or Orchestration (a central controller service dictates the workflow).
4. Key Design Principles for Scalability & Resilience
To build a microservices ecosystem that survives production traffic, you must adhere strictly to core design principles. The Single Responsibility Principle is paramount: each microservice should do exactly one thing well. If a service is handling both user profiles and billing logic, it needs to be split.
This leads directly to Loose Coupling & High Cohesion. Services should be completely independent of each other (loose coupling) while ensuring that related logic is kept together (high cohesion). A change in one service should theoretically never require a simultaneous code change in another service.
Because network calls fail, Fault Tolerance must be designed into the architecture from day one. You must implement patterns like retry logic with exponential backoff and Circuit Breakers. A circuit breaker detects when a downstream service is failing and temporarily blocks all traffic to it, preventing cascading failures across your entire cluster while giving the struggling service time to recover.
Finally, Observability (Logging, Metrics, Tracing) is non-negotiable. When a request traverses five different microservices before failing, you cannot SSH into a single server to debug it. You need centralized logging (like ELK), standardized metrics (like Prometheus), and distributed tracing (like Jaeger) to visualize exactly where the latency or exception occurred in the chain.
5. Conclusion & Next Steps
Transitioning from a monolithic monolith to a microservices architecture is not a silver bullet—it is a trade-off. You are trading the complexities of a massive, unmanageable codebase for the operational complexities of distributed systems. However, when executed correctly, the benefits are unparalleled: independent deployments, massive horizontal scalability, fault isolation, and the freedom to mix and match technology stacks.
If you are just starting this journey, I highly encourage you to get hands-on. Start small. Learn how to containerize applications using Docker, orchestrate them natively with Kubernetes, and visualize their health with Prometheus and Grafana. The best way to learn distributed systems is to build one.
What are your experiences with microservices? Have you battled the complexities of asynchronous debugging, or perhaps slain a monolith recently? Let me know in the comments or reach out—I'd love to hear your story.
Related Posts

How to Write Your First React App (Complete Beginner Guide to React & JavaScript)
If you know basic HTML and want to move into modern web development, React is one of the best places to start. Build your first React app step by step.

Why Small Businesses in Nepal Are Easy Targets for Cyber Attacks (And How to Fix It)
As Nepal's digital economy surges with eSewa, Fonepay, and social media commerce, small businesses are increasingly falling victim to cyber attacks. Here's why it happens and how you can stop it.
Building Modern UIs with React and Tailwind CSS
Practical tips and patterns for building beautiful, responsive user interfaces using React components styled with Tailwind CSS utility classes.